
想象一下這樣的日常:你坐進駕駛座,目的地已在云端同步。車輛自主駛出地庫,流暢匯入晚高峰車流。當路邊突然沖出一個騎自行車的行人,車身迅速微調方向、輕點剎車,提前半秒避讓險情。
更細節一些:車輛搭載的智能駕駛輔助系統能通過道路上的持續動態,預測前方路面的風險,調整車速和底盤姿態。
這一切,不再只是智駕模型通過感知當下而做出的行為,而是基于對物理世界的深度推演。讓智能駕駛擁有這種“預判與推演”能力的核心,正是世界模型。
它通過超大規模融合多模態數據,包括數百萬公里真實路況、仿真場景與交通規則,構建出一個動態、可推理的數字化交通世界。車輛不再僅僅“看到”障礙物,更能理解“為什么”。

(圖源:華為官網)
簡單來說,世界模型讓車擁有了“預判的腦子”,而不只是“反應的眼睛”。這一能力,正逐步落地成為現實。
今年4月,華為乾崑推出了全新升級的ADS 4系統,標志著高階輔助駕駛進入全新階段。它背后依托的,正是華為乾崑自研的WEWA架構(World Engine & World Behavior Architecture):包含云端的世界引擎(WE)與車端的世界行為模型(WA)。其中WE負責海量數據訓練與場景生成,WA則實現車端的實時環境推理與擬人化決策。
不獨華為,在2025年,包括小鵬、商湯等在內的科技公司,都已將世界模型視為實現自動駕駛的必經之路。
今年9月,華為乾崑智駕ADS 4將陸續上車。這次大規模上車的背后,世界模型量產上車風潮有望再起,智能駕駛核心邏輯正發生轉變:系統不再僅僅學習人類駕駛行為,而是開始理解物理規律本身。
自動駕駛的目標,不再只是學習“人類怎么做”,而是開始思考“怎樣做更好”,讓駕駛更安全。
端到端之后,智駕尋找“世界模型”
從依賴算力、規則驅動,到引入端到端模型,智能駕駛技術演進至今,一些根本挑戰仍未徹底解決。
2024年,在特斯拉技術路線的催化與主機廠“無圖開城”戰役陸續收尾之后,行業迅速調轉方向,集體駛向“端到端”。但越來越多玩家意識到,傳統的端到端模型并非完美解藥——它極度依賴高質量、大規模的真實駕駛數據去做行為“克隆”,本質上是在“模仿人”,而非真正理解物理世界或實現認知跨越。
舉例來講,現實道路上如果90%的司機在復雜路口選擇剎車觀望,僅有10%能夠流暢通過,這時候智駕系統更可能學會的是“保守停車”而非“精準決策”。它不辨別行為對錯,只模仿概率分布;不追求最優解,只擬合常態。
訓練這樣一個模型,你很難指望它自然“學”成頂尖高手,更可能的結果是開得越來越像一個“平均水平的司機”——猶豫、保守,甚至繼承了人類駕駛行為中所有的常見缺陷。
在人工智能領域,端到端模型符合典型的Scaling Law(規模法則)特性:模型性能隨數據量、參數規模和算力增長而提升,且尚未見頂。數據越多、模型越大、算力越強,它的駕駛表現就越擬人、越流暢。
但Scaling Law的另一面是,它無法超越數據本身的品質與分布。有哈佛等院校的研究人員曾在去年發布的一篇論文中指出,低精度訓練會降低模型的“有效參數量”。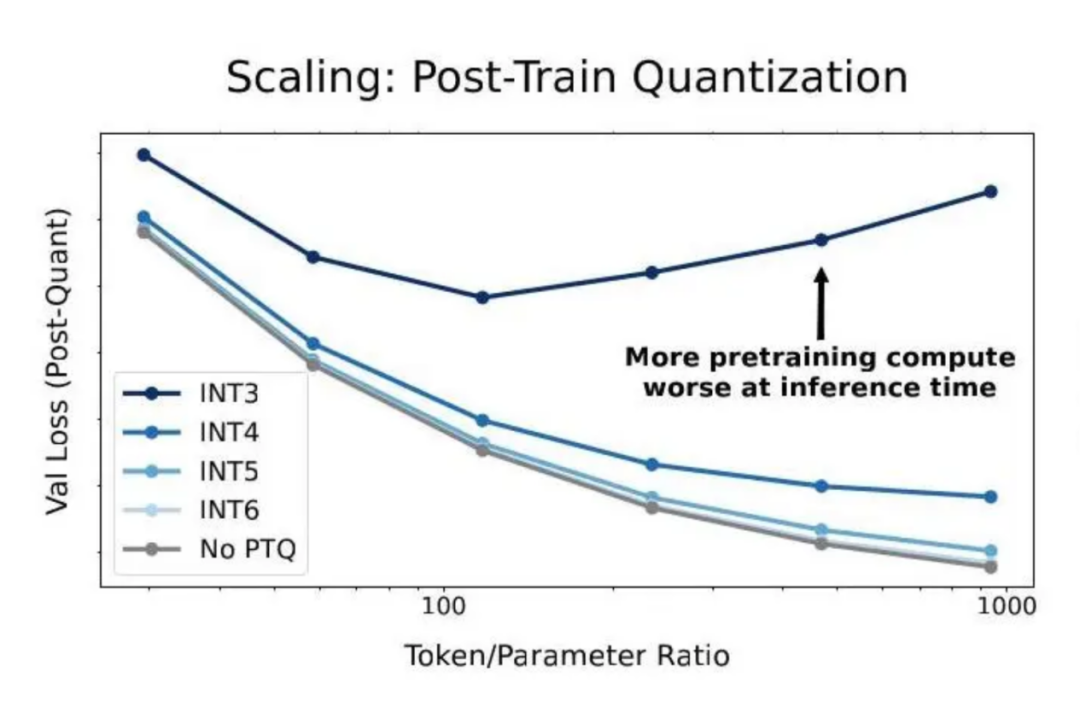
(圖為論文《scaling law for precision》中提出的研究量化圖,在訓練后期,用的訓練數據越多,量化之后模型性能下降得越厲害)
也因此,面對真實世界中層出不窮的罕見場景,端到端模型依然會暴露泛化能力的天花板。在此背景下,行業不再爭論“要不要轉向端到端”,而是探求如何實現“更安全的自動駕駛”。
世界模型就是在這樣的背景下誕生的。2025年伊始,主機廠和智駕供應商們正在做一道關于自動駕駛技術路徑的選擇題:
- 選項A是徹底拋棄模塊化設計、直接采用“一段式”端到端,或保留感知決策層、規劃控制層模塊,進行“兩段式”端到端方案;
- 選項B是引入視覺語言模型(VLA/VLM),嘗試用多模態大模型重構整個駕駛交互邏輯;
- 選項C則是加入世界模型,讓系統學會理解、預測并推理物理世界的運行機制。
世界模型之所以被推至臺前,根本上是為了解決端到端模型“只會模仿、不會思考”的瓶頸。
它的思路并不復雜:不再僅僅依靠人類駕駛數據去“模仿”,而是嘗試讓AI真正理解駕駛環境、預測未來變化,甚至自主生成合理的行為鏈,靠的是融合深度學習與思維鏈(CoT)推理框架。這種架構能夠自主生成連續推理鏈條,逐步突破長思維邏輯的局限,從而大幅提升復雜環境中的判斷能力。
在此程度上,世界模型不僅解決了訓練數據稀缺和質量不均的問題,更打開了模型能力的天花板。
在智駕路線的“大遷徙”中,整個智駕供應商的排名也大有變化,但華為乾崑依舊是穩居第一梯隊的那位。根據佐思汽研發布的調研數據,2024年,在國內三方前裝輔助駕駛域控全棧軟硬一體方案市場中,華為乾崑以79.0%的絕對市場份額穩居第一。
(圖源:佐思汽研)
華為乾崑之所以能持續領跑,不在于盲目追隨技術熱點,而在于其圍繞駕駛本質,走了一條更底層、更專注空間推理的路徑。2025年4月,華為乾崑在第一梯隊智駕供應商中率先發布了基于世界模型的乾崑智駕ADS 4系統。9月起,乾崑智駕ADS 4將開始陸續推送。
真正體現出華為乾崑差異化的,是在行業熱議“端到端”和“VLA(視覺語言模型)”路徑時,它始終走自己的路。
以VLA為例,這類方法嘗試在自動駕駛系統中引入大語言模型,將視覺信號先轉成文本描述,再推理成駕駛動作。它優勢明顯:理解路標、交規等語義信息更加輕松,也容易復用現成的大模型技術。
但華為乾崑看到其短板:語言模型擅長文本推理,卻缺乏對三維空間的精確感知與運動推演能力。而車,畢竟是在真實空間中運動的物體,毫厘之差可能就意味著風險。
“華為不會走向VLA的路徑。我們認為這樣的路徑看似取巧,其實并不是走向真正自動駕駛的路徑。華為更看重WA(世界行為模型),也就是world action,中間省掉language這個環節。”華為智能汽車解決方案BU CEO靳玉志說。
在2024年華為聯合浙江大學發布的一則論文中,華為就提出了Drive-OccWorld,這是一種以視覺為中心的世界模型,能夠借助世界模型所具備的“記憶”與“推演”能力——積累環境知識、預測未來狀態,從而提升自動駕駛系統的規劃表現,進一步增強端到端規劃的安全性與穩健性。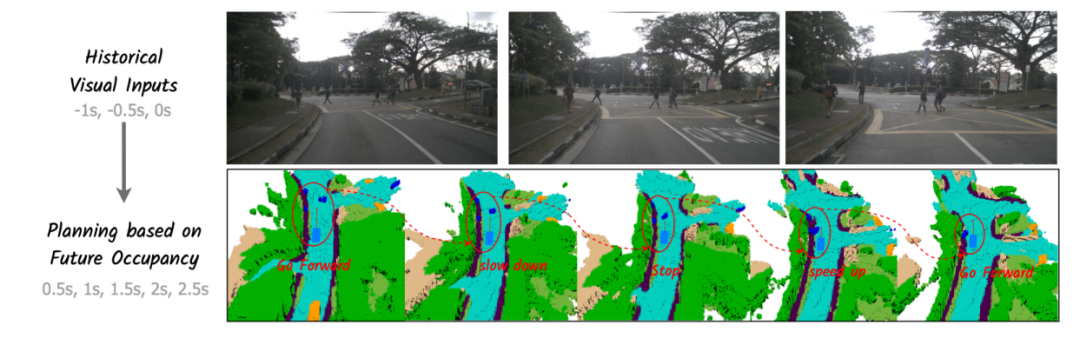
(本圖展示了行人橫穿馬路場景下,世界模型依據前三幀歷史圖像(上圖),對未來兩秒的占據狀態進行的動態預測(下圖)。紅色圓圈標示出了場景中的顯著移動物體。圖源:華為聯合浙江大學發布的《Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving》)
用更系統的模型設計,重塑智駕天花板
業界實踐也在表明,世界模型已成共識。
2023年,特斯拉在當年的CVPR2023上就已經展示了其世界模型的研究動態,但當時研發尚處于初期,馬斯克推崇的也是擴散模型diffusion。此前有觀點認為,Diffusion模型逐步refine預測的過程,可能更接近人類的認知和創造過程,比一些一步到位的生成方式更有潛力。

(圖源:X平臺)
在中國市場,蔚來和小鵬則是目前主要在實踐世界模型的主機廠。2024年,蔚來發布了中國首個智能駕駛世界模型NWM(NIO World Model),蔚來的世界模型具備多模態自回歸特性,能夠在100毫秒內推演出216種可能場景/軌跡。
小鵬依賴的是海量算力和數據訓練驅動高階智駕。目前,小鵬設計的是云端大模型(即世界基座模型)和車端小模型并進的路子。云端大模型負責“強化學習”和知識創造,車端小模型將知識轉化為瞬間的駕駛決策。在小鵬的云端大模型中,LLM(大語言模型)是其骨干,其VLA路徑需將視覺等信息轉換成語言的token進行訓練,再生成控制動作。
與它們相比,華為乾崑的模型架構與眾不同,反而選擇一條擺脫了語言中介的、更穩妥、卻也更為系統的路。
其核心創新,是構建了“云端世界引擎(WE)+車端世界行為模型(WA)”的雙層認知架構。前者致力于高效生成和迭代極端場景,實現“以AI訓練AI”;后者則融合多模態感知信號,實現實時推理與擬人化控制——相當于為智能駕駛系統裝上雙重大腦。

(圖為華為的WEWA架構)
在云端,華為乾崑依托自研的生成式模型,專注于自動駕駛中最稀缺的極端場景生成。
生成用于訓練的場景最基礎且重要的在于場景的真實性,行業普遍采用的Diffusion Transformer或3D高斯散射(3DGS),固然能生成豐富圖像和3D場景,但仍面臨“好看不一定好用”的問題——生成的數據是否合乎物理規律、能否精準覆蓋系統薄弱環節,才是關鍵。
華為乾崑的差異化在于兩點:一是生成“難題”,自研生成模型不強求通用能力,而是專注Corner Case,如突然橫穿的行人、暴雨中的滾動障礙物,采集難以獲得的高價值場景;二是閉環真實,通過嚴格算法校驗,確保合成場景的光照、材質、運動符合真實世界物理,不讓有缺陷的仿真數據污染系統認知。
簡單來說,華為乾崑WE的本質,是用AI給智駕系統“出難題”,而且出的是“真難題”,從而系統性地錘煉出一套更穩健、更安全的駕駛能力。
為了兜底安全,華為乾崑也云端設計了一套獎懲函數——Reward獎懲函數,以訓練模型的安全、合規、可靠且符合人類價值觀的決策和行為能力。
在車端,與行業普遍采用“用語言大模型改造智駕模型”的思路不同,華為乾崑的世界行為模型(WA)選擇了一條更專注、更高效的路徑:它是從零開始訓練的、專為智能駕駛而生的行為模型。
靳玉志透露,WA就是直接通過行為端,或者說直接通過vision這樣的信息輸入控車,這里的vision只是一個代表,它可能來自于聲音,可能來自于vision,也可能來自于觸覺。
關鍵在于“專用”而非“復用”。語言大模型雖然文本推理能力強,但缺乏對空間、距離、速度的本體感知,把駕駛決策交給它,好比讓一位語言學家去學開車——他雖然能讀懂交規,卻很難瞬間判斷剎車距離或障礙物方位。
這意味著,華為乾崑的WA模型不一定參數規模最大,但它一定最懂“車該怎么開”——它專為安全行駛而來,不為流暢對話而生。

(圖源:華為官網)
除了模型架構,華為乾崑在智能駕駛領域還擁有一個更為直觀的競爭優勢:規模龐大的真實車隊,使其規模化落地方面步伐更快。
靳玉志近日宣布,乾崑智駕系統的搭載量已突破100萬輛,覆蓋包括東風、長安、廣汽、北汽、比亞迪、賽力斯、奇瑞、江淮在內的11家車企、28款車型,未來新上市的車型還包括問界新M7、尚界H5、廣汽傳祺向往S9等。目前,華為上車的速度還在加快,靳玉志透露,華為乾崑智駕方案目前匹配一款車型最快僅需6至9個月。
這支百萬量級的“智能車隊”中,每一輛車都在實時反饋復雜場景:
- 數據持續流向云端,經過世界引擎(WE)的篩選、重建和增強,生成更有效的訓練場景,迭代出更可靠的駕駛模型。
- 與此同時,車端的世界行為模型(WA)同步發揮著“實時推理引擎”的作用,它接收云端下發的優化模型,在本地融合多模態感知數據,再對周圍環境進行精準理解與秒級決策。
新模型再通過OTA迅速部署回車端,推動全車隊整體進化——華為乾崑借此構建了一個“感知-云端訓練-車端進化”的自主進化閉環。
這一能力閉環,也為華為乾崑邁向更高階自動駕駛鋪平道路。它不只支撐現有的L2+系統優化,更在為L3及以上級別的自動駕駛做準備。規模化的真實數據、專用化的世界模型,加上清晰一致的技術路線,共同構成華為乾崑在智駕競賽中最堅實的護城河。








